
Written by: Medha Banerjee
Table of Contents
Introduction to Data Pipeline Management
The effective management of data pipelines has emerged as a pivotal factor in fostering sustainable growth and competitiveness. As organizations gather and process vast volumes of information, the flow of data management across various stages becomes paramount. A data pipeline is an architecture or system that allows businesses to move a huge amount of data from its source to the destination while performing numerous operations on the data along the way. This process involves extracting data from the database, transforming that data into a completely different format, cleaning that data, and loading it into another data storage system or database.
This article delves into the critical role of data pipeline management in facilitating informed decision-making, enhancing operational efficiency, and unlocking actionable insights, ultimately propelling businesses toward strategic expansion and innovation.
Book a demo to experience the meaningful insights we derive from data through our analytical tools and platform capabilities. Schedule a demo today!
Request a Free Demo
What is Data Pipeline Management: An industry Overview

A data pipeline involves extracting raw data from various sources, transforming it, and then transferring it to a centralized repository for analysis, such as a data lake or warehouse. Pre-processing steps ensure proper integration and standards like masking and aggregations, critical for relational databases. Data pipelines support data science and BI by sourcing from diverse sources but often require preprocessing. Tracking data lineage records connections between company data across applications, aiding in BI dashboards’ effectiveness.
Transforming Business with Data Pipeline Automation: A Quantzig Success Story
| Category | Details |
|---|---|
| Client Details | A leading Retail company located in the USA |
| Challenges | Data silos hindered cross-functional collaboration and caused redundancies. Poor data quality impeded decision-making and strategy development. Security vulnerabilities risked data breaches and compliance issues. Complex data landscape overwhelmed existing infrastructure, impeding integration and analysis. |
| Solutions Offered | No-code data pipeline solution automated data tasks related to management, governance, and monetization. Simplified data integration, eliminated silos, and provided a unified view of operations. Enhanced data quality with real-time cleansing and validation. Improved data security with robust access controls and encryption measures. |
| Impact Delivered | 70% reduction in manpower needed for data pipelines. 30% reduction in TCO of data pipelines and a 35% reduction in infrastructure costs. |
Challenges faced by the Client:
Before engaging with Quantzig, the retail client faced challenges due to data silos, hindering cross-functional collaboration and causing redundancies. Data quality issues, including inaccuracies and inconsistencies, compromised decision-making. Security vulnerabilities in sensitive data raised concerns about breaches and compliance. The complexity of diverse data types overwhelmed existing infrastructure, impeding integration and analysis.
Solutions Offered by Quantzig:
Quantzig’s no-code data pipeline transformed our retail client’s data management. Automating tasks in management, governance, and monetization, it simplified integration from diverse sources, eliminating silos. This unified data hub accelerated decision-making with accurate insights. It enhanced data quality, detecting and rectifying inaccuracies in real-time, bolstering confidence in strategic decisions.
Impact Delivered after Quantzig’s Data pipeline Management Solution was implemented:
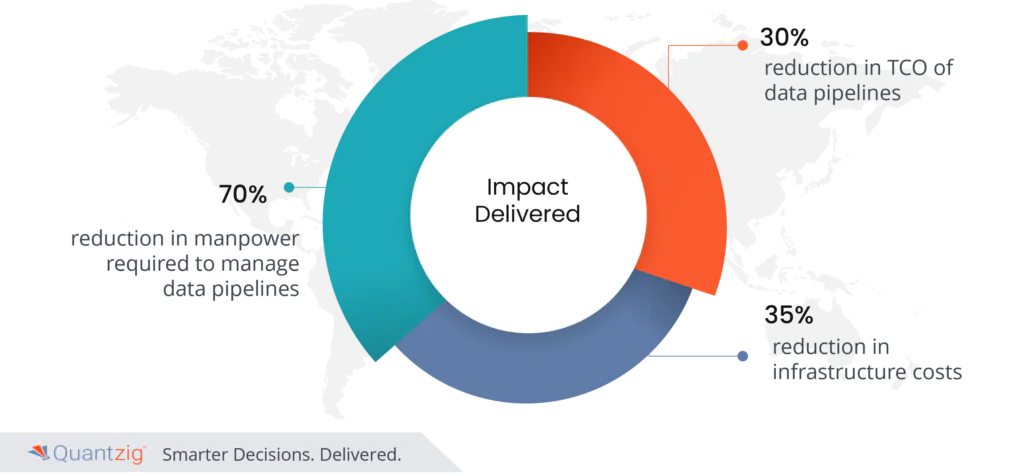
- 70% reduction in manpower required to manage data pipelines.
- 30% reduction in TCO of data pipelines.
- 35% reduction in infrastructure costs
Experience the advantages firsthand by testing a customized complimentary pilot designed to address your specific requirements. Pilot studies are non-committal in nature.
Request a free pilot4 Key benefits of data pipeline management To Help your business growth:
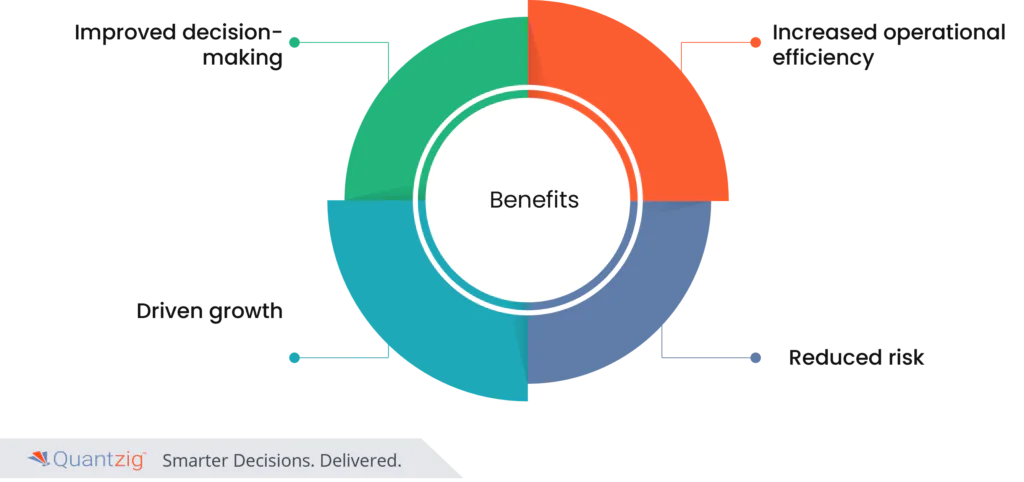
Effective data pipeline management enhances decision-making by providing timely, accurate data for product, service, and marketing decisions, boosting sales, customer satisfaction, and cost savings. By automating data processes, it improves operational efficiency, streamlining resource allocation and enabling faster responses to market changes. Moreover, data pipelines drive growth by consolidating data for identifying opportunities, informing strategic decisions, and supporting targeted marketing campaigns. They also mitigate risks by ensuring data accuracy, security, and compliance, safeguarding against fraud and maintaining customer trust. Overall, well-managed data pipelines contribute to business growth by reducing risks, enhancing credibility, and enabling expansion into new opportunities.
Get started with your complimentary trial today and delve into our platform without any obligations. Explore our wide range of customized, consumption driven analytical solutions services built across the analytical maturity levels.
Start your free trial
What Is the Difference Between a Data Pipeline and ETL?
A data pipeline is a broader concept that encompasses various ways of processing data. ETL (Extract, Transform, Load) is one specific method used within a data pipeline. ETL is a three-step process that involves:
- Extracting data from a source
- Transforming or modifying the data in a temporary destination
- Loading the transformed data into a final repository, such as a cloud data lake, data warehouse, or application
ETL has traditionally been used for batch processing of large amounts of data. However, real-time or streaming ETL has become more popular as organizations have access to always-on data.
Top 4 Use Cases using Data Pipeline Best Practices
Data management is becoming more and more important as big data grows. Although data pipelines have many uses, the following are specific to commercial applications:
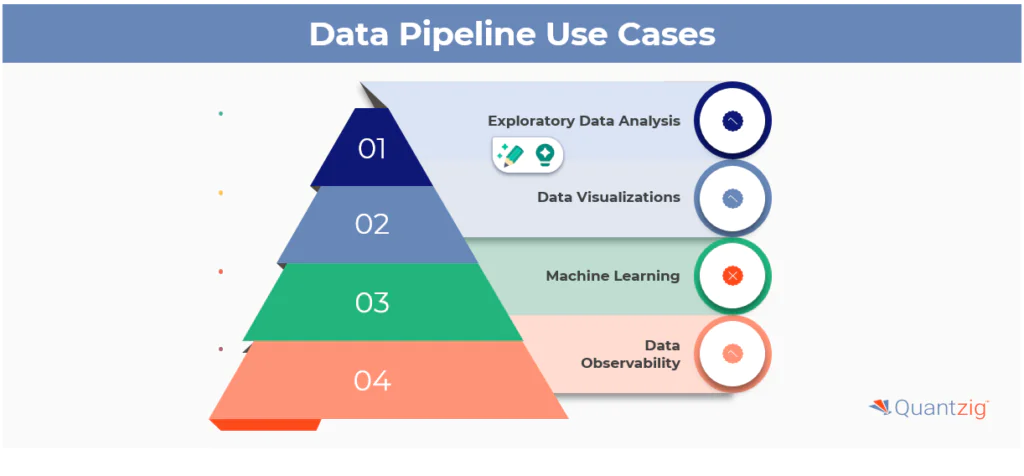
Exploratory data analysis (EDA) allows data scientists to analyze and summarize primary dataset features, often using visualization techniques for pattern recognition and anomaly detection. Data visualizations, such as charts and infographics, simplify complex data relationships and insights. Machine learning employs data and algorithms to simulate human learning processes, deriving predictions and classifications in data mining. Data observability ensures data reliability and security through tracking, monitoring, and alerting.
How to Build an Efficient Data Pipeline in 6 Steps
Building an efficient data pipeline involves the following six steps:
- Cataloging and governing data to enable access to trusted and compliant data at scale across an enterprise.
- Efficiently ingesting data from various sources, such as on-premises databases or data warehouses, SaaS applications, IoT sources, and streaming applications, into a cloud data lake.
- Integrating data by cleansing, enriching, and transforming it, creating zones like a landing zone, enrichment zone, and an enterprise zone.
- Applying data quality rules to cleanse and manage data while making it available across the organization to support DataOps.
- Preparing data to ensure that refined and cleansed data moves to a cloud data warehouse for enabling self-service analytics and data science use cases.
- Stream processing to derive insights from real-time data coming from streaming sources like Kafka and then moving it to a cloud data warehouse for analytics consumption.
Data Pipeline Best Practices
Organizations should adhere to key practices for robust data pipeline implementation. Essential considerations include seamless deployment across cloud ecosystems, efficient data ingestion from diverse sources, and real-time schema drift detection for synchronization. A user-friendly interface, automation features, and managed serverless deployment enhance productivity and operational efficiency. Data quality rules should be applied for effective cleansing and standardization.


